

[vc_row][vc_column][vc_column_text]تصور کنید که در یک نمایشگاه هنری در گالری مشهور گاگوسیان قدم میزنید، جایی که به نظر میرسد نقاشیها ترکیبی از سورئالیسم و دقت واقعی هستند. یک قطعه نظر شما را جلب میکند: کودکی را با موهای پرتاب شده به تصویر میکشد که به بیننده خیره شده است و با رنگ آمیزی آن حس دوران ویکتوریا را تداعی میکند. اما پیچ و خم اینجاست، این آثار دست انسان نیستند، بلکه ساختههای هوش مصنوعیاند، تولید تصویر با هوش مصنوعی چقدر پیشرفت کرده است؟
این نمایشگاه که توسط کارگردان فیلم بنت میلر تهیه شده است، ما را وادار میکند تا ماهیت خلاقیت و اصالت را زیر سوال ببریم زیرا هوش مصنوعی (AI) شروع به محو کردن خطوط بین هنر انسانی و تولید ماشین میکند. جالب اینجاست که میلر چند سال گذشته را صرف ساختن مستندی درباره هوش مصنوعی کرده است که طی آن با سم آلتمن، مدیر عامل OpenAI، مصاحبه کرده است. این ارتباط باعث شد که میلر به زودی به DALL-E دسترسی بتا پیدا کند، که سپس از آن برای خلق آثار هنری نمایشگاه استفاده کرد.
اکنون، این مثال ما را به قلمروی جذاب میاندازد که در آن تبدیل متن به عکس هوش مصنوعی و ایجاد محتوای بصری غنی در خط مقدم قابلیتهای هوش مصنوعی قرار دارد. صنایع و خلاقان به طور گستردهای از هوش مصنوعی برای ایجاد تصویر استفاده میکنند و درک این موضوع ضروری است: چگونه باید به تولید تصویر از طریق هوش مصنوعی برخورد کرد؟
تولید تصویر با هوش مصنوعی چیست؟

مولدهای تصویر هوش مصنوعی از شبکههای عصبی مصنوعی آموزش دیده برای ایجاد تصاویر استفاده میکنند. این زایندهها ظرفیت ایجاد تصاویر واقعی را بر اساس ورودی متنی ارائه شده به زبان طبیعی دارند. چیزی که آنها را قابل توجه میکند توانایی آنها در ترکیب سبکها، مفاهیم و ویژگیها برای ساختن تصاویر هنری و مرتبط با زمینه است. این امر از طریق هوش مصنوعی زاینده Generative AI، زیرمجموعهای از هوش مصنوعی که بر تولید محتوا متمرکز است، امکان پذیر شده است.
مولدهای تصویر هوش مصنوعی بر روی حجم وسیعی از دادهها آموزش دیدهاند که شامل مجموعه دادههای بزرگی از تصاویر است. از طریق فرآیند آموزش، الگوریتمها جنبهها و ویژگیهای مختلف تصاویر را در مجموعه دادهها یاد میگیرند. در نتیجه، آنها قادر به تولید تولید تصویر با هوش مصنوعی میشوند که شباهتهایی از نظر سبک و محتوا با تصاویر موجود در دادههای آموزشی دارند.
طیف گستردهای از تولید کنندههای تصویر هوش مصنوعی وجود دارد که هر کدام دارای قابلیتهای منحصر به فرد خود هستند. نکته قابل توجه در این میان، تکنیک انتقال سبک عصبی است که امکان تحمیل سبک یک تصویر را به دیگری فراهم میکند.
شبکههای متخاصم مولد (GANs)، که از دو شبکه عصبی برای آموزش تولید تصاویر واقعی شبیه به تصاویر موجود در مجموعه داده آموزشی استفاده میکنند. و مدلهای انتشار، که تصاویر را از طریق فرآیندی شبیهسازی میکنند که انتشار ذرات را شبیهسازی میکند و به تدریج نویز را به تصاویر ساختاریافته تبدیل میکند.
نحوه کار مولدهای تصویر هوش مصنوعی: مقدمهای بر فناوریهای تولید تصویر با هوش مصنوعی
در این بخش، عملکرد پیچیده تولیدکنندههای تصویر هوش مصنوعی برجسته را بررسی میکنیم و بر نحوه آموزش این مدلها برای ایجاد تصاویر تمرکز میکنیم.
درک متن با استفاده از NLP

تولیدکنندههای تصویر هوش مصنوعی با استفاده از فرآیندی که دادههای متنی را به زبانی ماشینپسند ترجمه میکند، پیامهای متنی را درک میکنند. این تبدیل توسط یک مدل پردازش زبان طبیعی (NLP) آغاز میشود، مانند مدل پیشآموزشی زبان تصویر متضاد (CLIP) که در مدلهایی مانند DALL-E برای تولید تصویر با هوش مصنوعی استفاده میشود.
این مکانیسم متن ورودی را به بردارهایی با ابعاد بالا تبدیل میکند که معنی و بافت معنایی متن را به تصویر میکشد. هر مختصات روی بردارها نشان دهنده یک ویژگی متمایز از متن ورودی است.
مثالی را در نظر بگیرید که در آن کاربر اعلان متن “a apple red on a tree” را به یک تولید کننده تصویر وارد میکند. مدل NLP این متن را در قالبی عددی رمزگذاری میکند که عناصر مختلف – “قرمز”، “سیب” و “درخت” – و رابطه بین آنها را نشان میدهد. این نمایش عددی به عنوان یک نقشه ناوبری برای تولید تصویر با هوش مصنوعی عمل میکند.
در طول فرآیند ایجاد تصویر، این نقشه برای کشف پتانسیلهای گسترده تصویر نهایی مورد استفاده قرار میگیرد. اینکار به عنوان یک کتاب قانون عمل میکند که هوش مصنوعی را در مورد اجزاء، برای گنجاندن در تصویر و نحوه تعامل آنها راهنمایی میکند. در سناریوی داده شده، ژنراتور یک تصویر با یک سیب قرمز و یک درخت ایجاد میکند و سیب را روی درخت، نه در کنار آن یا زیر آن، قرار میدهد.
این تبدیل هوشمندانه از متن به نمایش عددی و در نهایت به تصاویر، تولیدکنندگان تصویر هوش مصنوعی را قادر میسازد تا اعلانهای متن را تفسیر و به صورت بصری نمایش دهند.
شبکههای متخاصم مولد (GAN)
شبکههای متخاصم مولد، که معمولاً GAN نامیده میشوند، کلاسی از الگوریتمهای یادگیری ماشین هستند که از قدرت دو شبکه عصبی رقیب، زاینده و متمایزکننده استفاده میکنند. اصطلاح «متخاصم» از این مفهوم ناشی میشود که این شبکهها در رقابتی شبیه به یک بازی با جمع صفر در مقابل یکدیگر قرار میگیرند.
در سال 2014، GANها توسط ایان گودفلو و همکارانش در دانشگاه مونترال زنده شدند. کار پیشگامانه آنها در مقالهای با عنوان “شبکههای متخاصم مولد” منتشر شد. این نوآوری جرقه ای از تحقیقات و کاربردهای عملی را برانگیخت و GANها را به عنوان محبوبترین مدلهای هوش مصنوعی زاینده در چشمانداز فناوری تثبیت کرد.
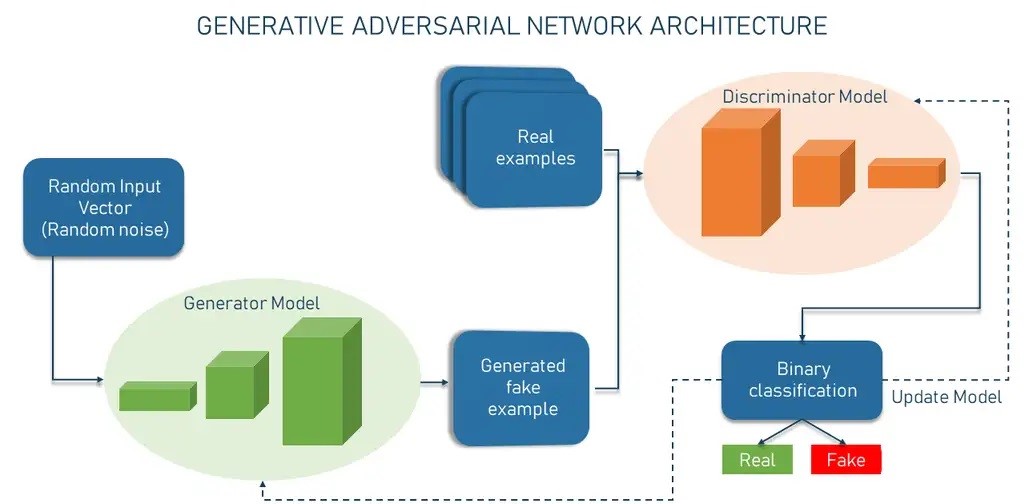
معماری GANها از دو جزء اصلی تشکیل شده که به عنوان مدلهای فرعی شناخته میشوند:
- شبکه عصبی ژنراتور مسئول تولید نمونههای جعلی است. یک بردار ورودی تصادفی – لیستی از متغیرهای ریاضی با مقادیر ناشناخته – میگیرد و از این اطلاعات برای ایجاد دادههای ورودی جعلی استفاده میکند.
- شبکه عصبی تفکیک کننده به عنوان یک طبقهبندی کننده باینری عمل میکند. نمونه ای را به عنوان ورودی میگیرد و تعیین میکند که آیا واقعی است یا توسط ژنراتور تولید شده.
تمامی این اجزا سبب تولید تصویر با هوش مصنوعی میشوند.
مدلهای انتشار (Diffusion)
مدلهای انتشار نوعی مدل مولد در یادگیری ماشین هستند که با تقلید از دادههایی که روی آنها آموزش دیدهاند، دادههای جدیدی مانند تصاویر یا صداها را ایجاد میکنند. آنها این کار را با استفاده از فرآیندی شبیه به انتشار انجام میدهند، از این رو به آنها مدلهای انتشار میگویند. آنها به تدریج نویز را به دادهها اضافه میکنند و سپس یاد میگیرند که چگونه آن را معکوس کنند تا دادههای جدید و مشابه ایجاد کنند.
مدلهای دیفیوژن را بهعنوان سرآشپزهایی در نظر بگیرید که یاد میگیرند غذاهایی درست کنند که طعم آنهایی را که قبلاً امتحان کردهاند، داشته باشند. سرآشپز یک غذا را میچشد، مواد تشکیل دهنده را میفهمد و سپس یک غذای جدید درست میکند که طعم بسیار مشابهی دارد. به طور مشابه، مدلهای انتشار میتوانند دادههایی (مانند تصاویر) تولید کنند که بسیار شبیه آنهایی هستند که روی آنها آموزش دیدهاند.

بیایید با جزئیات بیشتر به این فرآیند نگاه کنیم.
انتشار به جلو (افزودن مواد به یک ظرف اصلی): در این مرحله، مدل با یک قطعه داده اصلی مانند یک تصویر شروع میشود و به تدریج نویز تصادفی را طی یک سری مراحل اضافه میکند. این کار از طریق یک زنجیره مارکوف انجام میشود که در هر مرحله، دادهها بر اساس وضعیت آن در مرحله قبل تغییر میکنند. نویز اضافه شده را نویز Gaussian مینامند که یک نوع رایج نویز تصادفی است.
آموزش (درک سلیقهها): مرحله بعدی در تولید تصویر با هوش مصنوعی آموزش است. در اینجا، مدل یاد میگیرد که چگونه نویز اضافه شده در طول انتشار به جلو، دادهها را تغییر میدهد. این نقشه سفر از دادههای اصلی به نسخه پر سر و صدا را ترسیم میکند. هدف این است که به خوبی در این سفر تسلط پیدا کنیم که مدل بتواند به طور موثر آن را به عقب هدایت کند. مدل یاد میگیرد که تفاوت بین دادههای اصلی و نسخههای نویز را در هر مرحله تخمین بزند. هدف از آموزش یک مدل انتشار، تسلط بر فرآیند معکوس است.
انتشار معکوس (بازسازی ظرف): پس از آموزش مدل، زمان معکوس کردن فرآیند فرا میرسد. دادههای نویزدار را میگیرد و سعی میکند نویز را حذف کند تا به دادههای اصلی بازگردد. این شبیه به دنبال کردن مجدد مراحل سفر است اما در جهت مخالف. با ردیابی مجدد مراحل در این جهت مخالف در امتداد دنباله، مدل میتواند دادههای جدیدی تولید کند که شبیه نمونه اصلی است.
تولید دادههای جدید (ساخت یک ظرف جدید): در نهایت، مدل میتواند از آنچه در فرآیند انتشار معکوس آموخته برای ایجاد دادههای جدید استفاده کند. با نویز تصادفی شروع میشود، که مانند یک دسته درهم از پیکسل است. در کنار آن، یک پیام متنی دریافت میکند که مدل را در شکل دادن به نویز راهنمایی میکند.
پرامپت متن مانند یک دستورالعمل است. به مدل میگوید که تصویر نهایی چگونه باید باشد. همانطور که مدل در مراحل انتشار معکوس تکرار میشود، به تدریج این نویز را به یک تصویر تبدیل میکند در حالی که سعی میکند اطمینان حاصل شود که محتوای تصویر تولید شده با اعلان متن همسو میشود. این کار با به حداقل رساندن تفاوت بین ویژگیهای تصویر تولید شده و ویژگیهایی که بر اساس اعلان متن مورد انتظار است، انجام میشود.
این روش یادگیری اضافه کردن نویز و سپس تسلط بر نحوه معکوس کردن آن چیزی است که مدلهای انتشار را قادر به تولید تصاویر با هوش مصنوعی و انواع دیگر دادههای واقعی میکند.
انتقال سبک عصبی (NST)
انتقال سبک عصبی (NST) یک برنامه یادگیری عمیق است که محتوای یک تصویر را با سبک تصویر دیگر ترکیب میکند تا یک اثر هنری کاملاً جدید ایجاد کند.

در سطح بالایی، NST از یک شبکه از پیش آموزش دیده برای تجزیه و تحلیل تصاویر استفاده میکند و از اقدامات اضافی برای قرض گرفتن سبک از یک تصویر و اعمال آن بر روی تصویر دیگر استفاده میکند. این منجر به ترکیب یک تصویر جدید میشود که ویژگیهای مورد نظر را گرد هم میآورد.
این فرآیند شامل سه تصویر اصلی است.
- تصویر محتوا : این تصویری است که میخواهید محتوای آن را حفظ کنید.
- تصویر سبک : این یکی سبک هنری را ارائه میدهد که میخواهید به تصویر محتوا تحمیل کنید.
- تصویر تولید شده : در ابتدا، این میتواند یک تصویر تصادفی یا یک کپی از تصویر محتوا باشد. این تصویر در طول زمان اصلاح میشود تا محتوای تصویر محتوا با سبک تصویر سبک ترکیب شود. این تنها متغیری است که الگوریتم در واقع در طول فرآیند تولید تصاویر با هوش مصنوعی تغییر میکند.
با بررسی این مکانیک، لازم به ذکر است که شبکه های عصبی مورد استفاده در NST دارای لایههایی از نورون هستند. لایههایی که اول ممکن است لبهها و رنگها را تشخیص دهند، اما هرچه به عمق شبکه میروید، لایهها این ویژگیهای اساسی را برای تشخیص ویژگیهای پیچیدهتر، مانند بافتها و اشکال، ترکیب میکنند. NST هوشمندانه از این لایهها برای جداسازی و دستکاری محتوا و سبک استفاده میکند.
با پیشرفت بهینهسازی، تصویر تولید شده محتوا و سبک را از تصاویر مختلف میگیرد. نتیجه نهایی ترکیبی جذاب از این دو است که اغلب شباهت زیادی به یک اثر هنری دارد.
مدلهای GAN، NST و Diffusion تنها چند فناوری تولید تصویر با هوش مصنوعی هستند که اخیراً توجهات را به خود جلب کردهاند. بسیاری از تکنیکهای پیچیده دیگر در این زمینه سریع و در حال تکامل در حال ظهور هستند، زیرا محققان همچنان مرزهای آنچه را که با هوش مصنوعی در تولید تصویر امکانپذیر است، پیش میبرند.
شما میتوانید همین حالا از طریق زبان فارسی به موتورهای هوش مصنوعی مولد مانند ChatGPT و سرویس تبدیل متن به عکس لئوناردو دسترسی پیدا کنید. تنها کافی است اپلیکیشن زیگپ را دانلود و به راحتی از آن استفاده کنید. همچنین شما میتوانید نظرات خود را با ما و سایر کاربران در شبکههای اجتماعی ما در اینستاگرام و تلگرام به اشتراک بگذارید.








